Elasticsearch默认的分词器会将中文比如”你好”拆分成”你”和”好”这两个字,然后按照倒排索引进行存储,所以默认的分词不好用,大部分时候都会自己更换分词器以达到预期的效果。推荐一个很好用的分词器,众所周知的IK分词器
简单介绍一下IK分词器中的ik_smart和ik_max_word,两者的区别就是分词粒度不一样
ik_smart:粗粒度分词
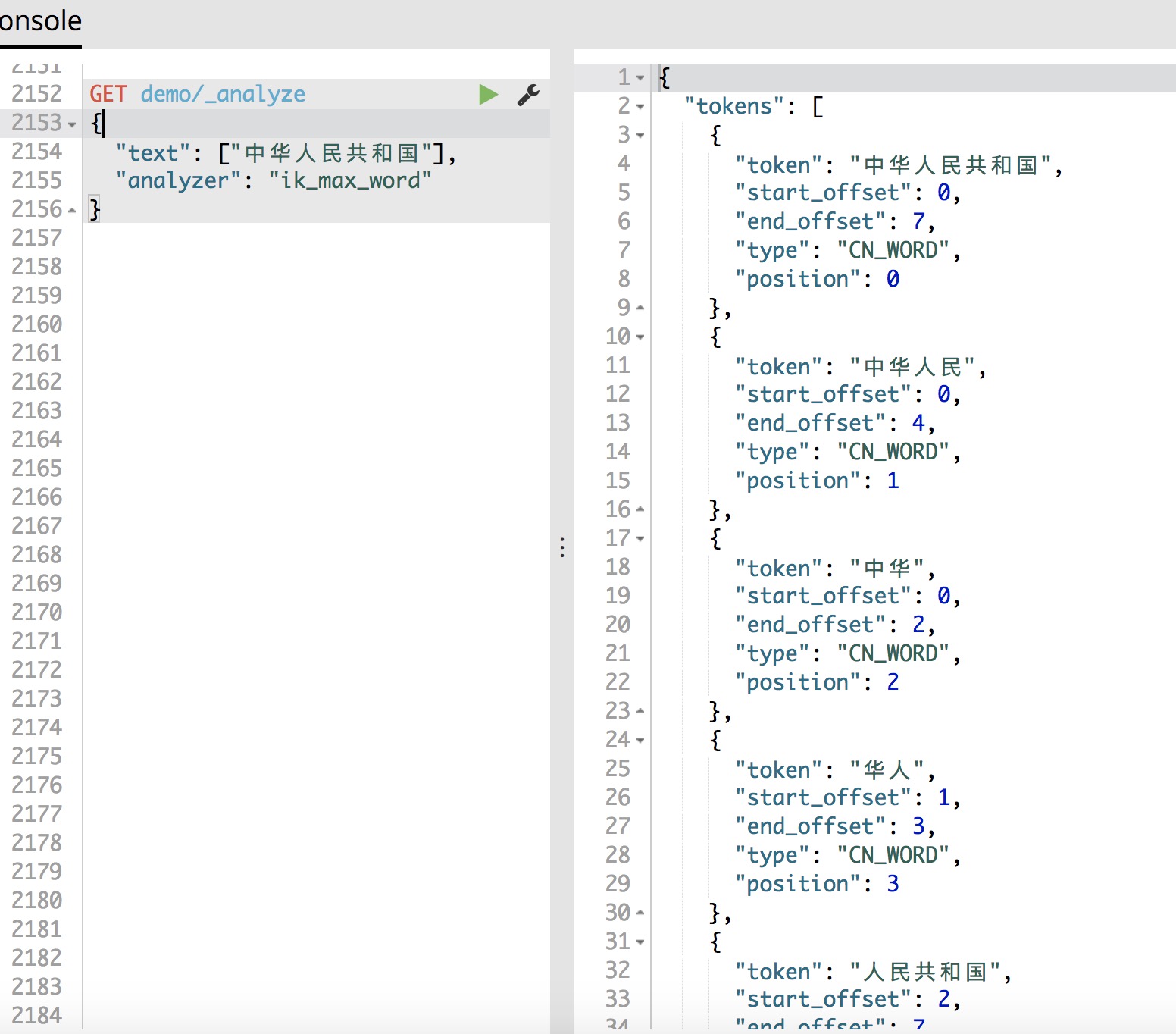
ik_max_word:细粒度分词,切分出的词尽可能的多
ik_smart粗粒度分词效果
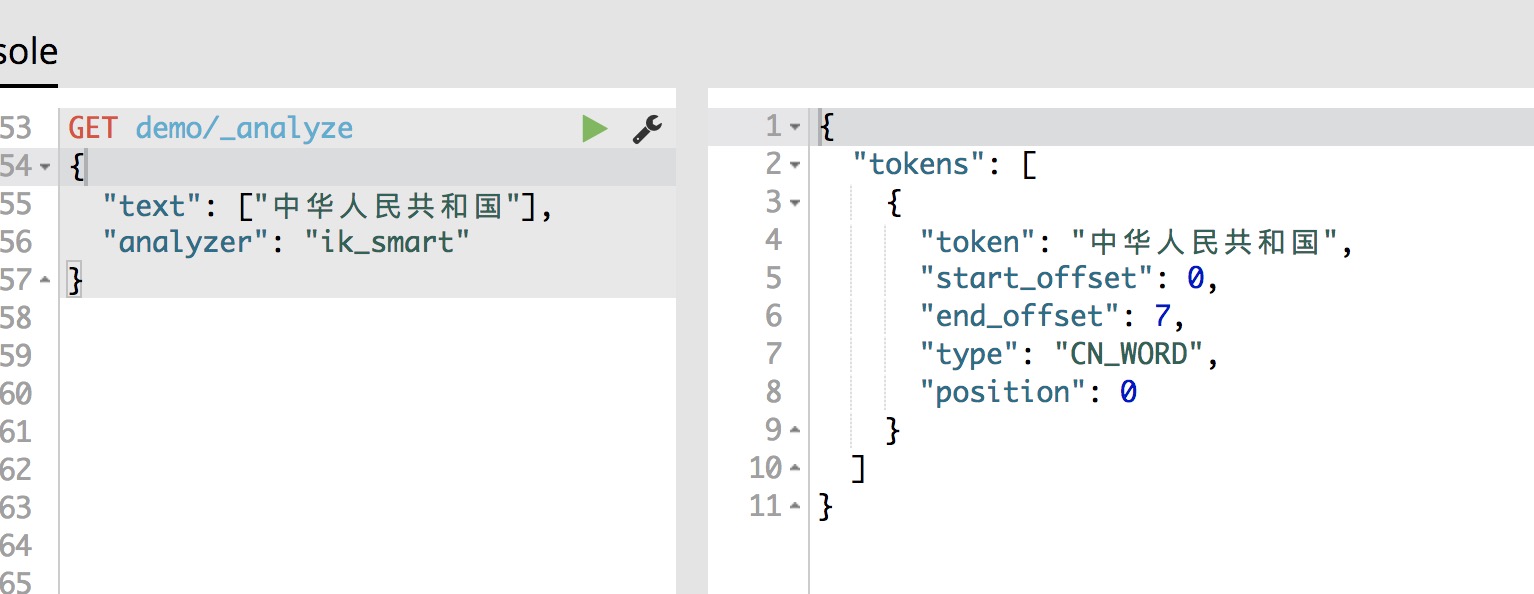
ik_max_word细粒度分词效果,可以看到切分出的词非常多,ik_smart切分的词只是ik_max_word分词后的子集
安装IK分词器,本人使用的Elasticsearch版本是5.5.3,安装IK需要把下面命令中的5.5.3更换成自己Elasticsearch的版本号,安装完后重启Elasticsearch
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.3/elasticsearch-analysis-ik-5.5.3.zip
IK分词器详细说明参见github文档
既然中文可以搜索,那么拼音也可以进行搜索,用户时常在输入中文的时候输成了拼音,为了提高UE,也应当返回搜索结果,就像百度搜索一样
再介绍一下拼音分词插件,本人使用的是elasticsearch-analysis-pin插件,同IK分词插件一样,也是elastic大咖medcl的项目,详细使用详情参见github,大咖常年活跃在elastic中文社区,很多问题在中文社区都能够得到有效的解决
安装方式,同样也要更换成Elasticsearch相对应的版本号
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v5.5.3/elasticsearch-analysis-pinyin-5.5.3.zip
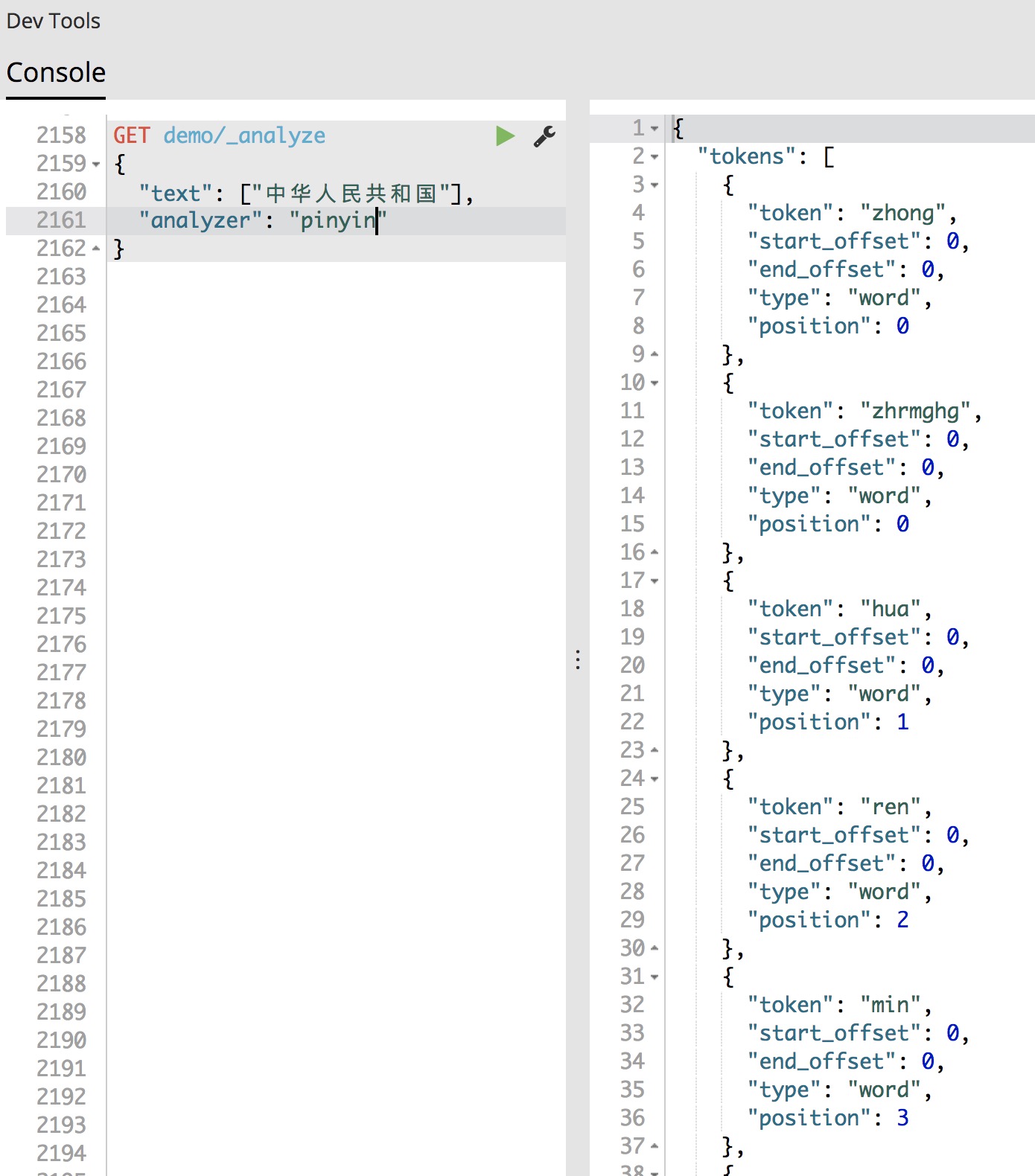
pinyin索引效果
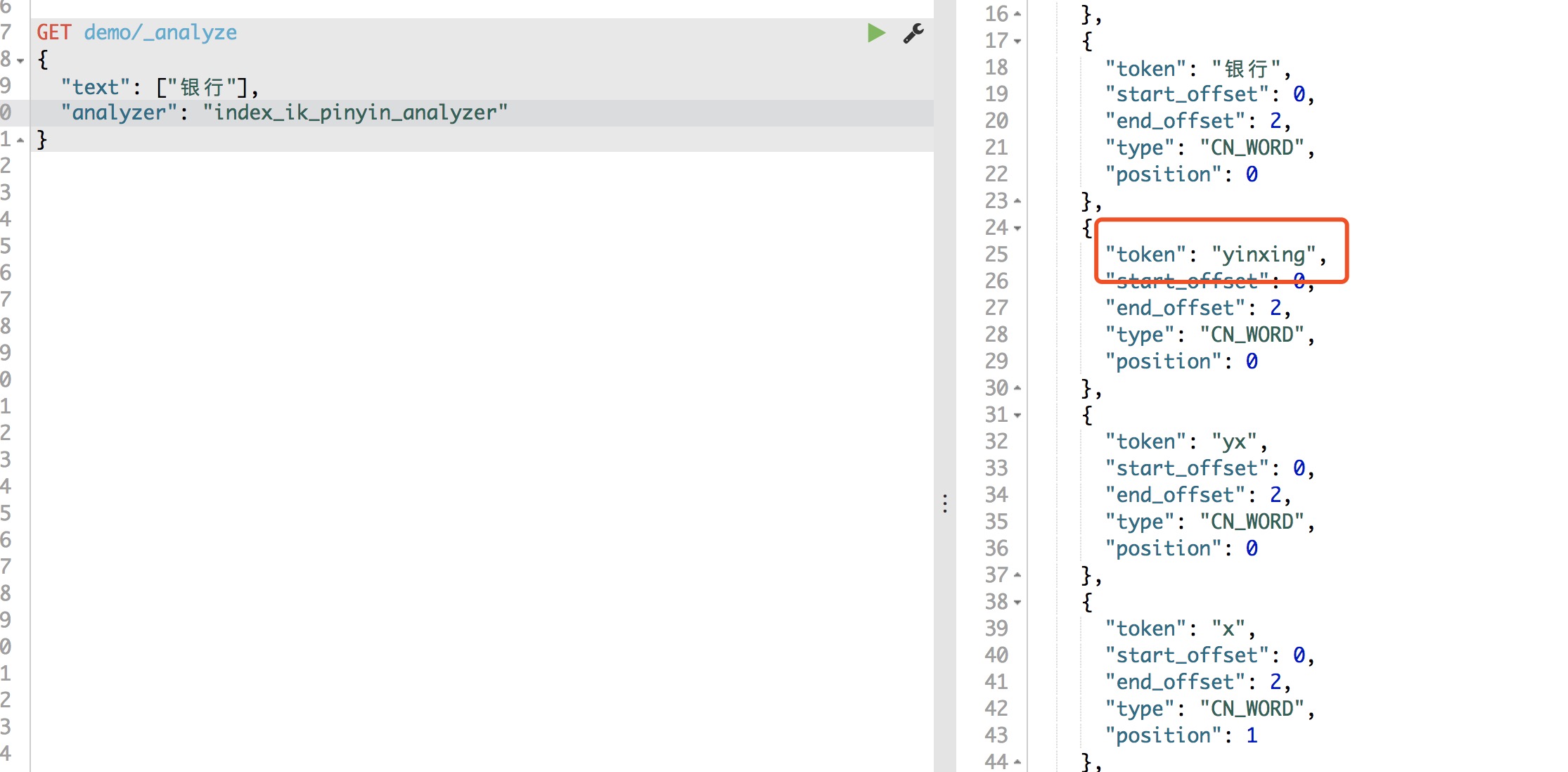
pinyin分词器存在一个问题就是多音字不好区分,NLP语义理解一直也是比较难的部分,例如下面就没有将“银行”的拼音正确解析
忘记介绍了,本人使用的搜索界面是kibana,是ELK组件中的K,E是Elaisticsearch,L是Logstash,L用于日志收集,界面插件有很多,Kibana还是很好用的,强烈安利一波,Elasticsearch+Kibana环境搭建还是很简单的,在此不做过多赘述
进入正题,我们想要实现上图中百度搜索这种效果就需要把pinyin和ik进行组合搜索。先自定义分词器
PUT demo
{
"index": {
"analysis": {
"filter": {
"index_pinyin": {
"type": "pinyin",
"keep_original": true,
"keep_first_letter": true,
"keep_separate_first_letter": true,
"keep_full_pinyin": true,
"keep_joined_full_pinyin": true,
"keep_none_chinese_in_joined_full_pinyin": false,
"keep_none_chinese_in_first_letter": false,
"none_chinese_pinyin_tokenize": false,
"first_letter": "prefix",
"padding_char": " ",
"lowercase" : true,
"remove_duplicated_term" : true
},
"search_pinyin": {
"type": "pinyin",
"keep_original": true,
"keep_first_letter": false,
"keep_separate_first_letter": false,
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_none_chinese_in_joined_full_pinyin": true,
"keep_none_chinese_in_first_letter": true,
"none_chinese_pinyin_tokenize": false,
"first_letter": "prefix",
"padding_char": " ",
"lowercase" : true,
"remove_duplicated_term" : true
},
"length":{
"type": "length",
"min":2
}
},
"analyzer": {
"index_ik_pinyin_analyzer": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": ["index_pinyin"]
},
"search_ik_pinyin_analyzer": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": ["length","search_pinyin","length"]
}
}
}
}
}
定义了两个分词器,analyzer中的index_ik_pinyin_analyzer和search_ik_pinyin_analyzer,在filter中定义了3个过滤器,两个是pinyin类型过滤器,还有一个是length过滤器,将分词后的长度最小值设置成2,也就是去掉长度为1的词
PUT demo/items/_mapping
{
"properties": {
"name":{
"type": "text",
"analyzer": "index_ik_pinyin_analyzer",
"search_analyzer": "search_ik_pinyin_analyzer",
"fields": {
"keyword":{
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
设置mapping,type为items,只设置了一个字段name,index_ik_pinyin_analyzer用于索引,search_ik_pinyin_analyzer用于搜索,在ES中,索引做为名词就是索引的意思,做为动词可以理解成存储的意思
通过bulk API批量操作数据
POST _bulk
{"index":{"_index":"demo","_type": "items","_id": 1}}
{"name": "美国"}
{"index":{"_index":"demo","_type": "items","_id": 2}}
{"name": "英国"}
{"index":{"_index":"demo","_type": "items","_id": 3}}
{"name": "中国"}
{"index":{"_index":"demo","_type": "items","_id": 4}}
{"name": "中华人民共和国"}
{"index":{"_index":"demo","_type": "items","_id": 5}}
{"name": "gongheguo"}
{"index":{"_index":"demo","_type": "items","_id": 6}}
{"name": "刘德华"}
{"index":{"_index":"demo","_type": "items","_id": 7}}
{"name": "刘青云"}
{"index":{"_index":"demo","_type": "items","_id": 8}}
{"name": "陕西省"}
{"index":{"_index":"demo","_type": "items","_id": 9}}
{"name": "山西省"}
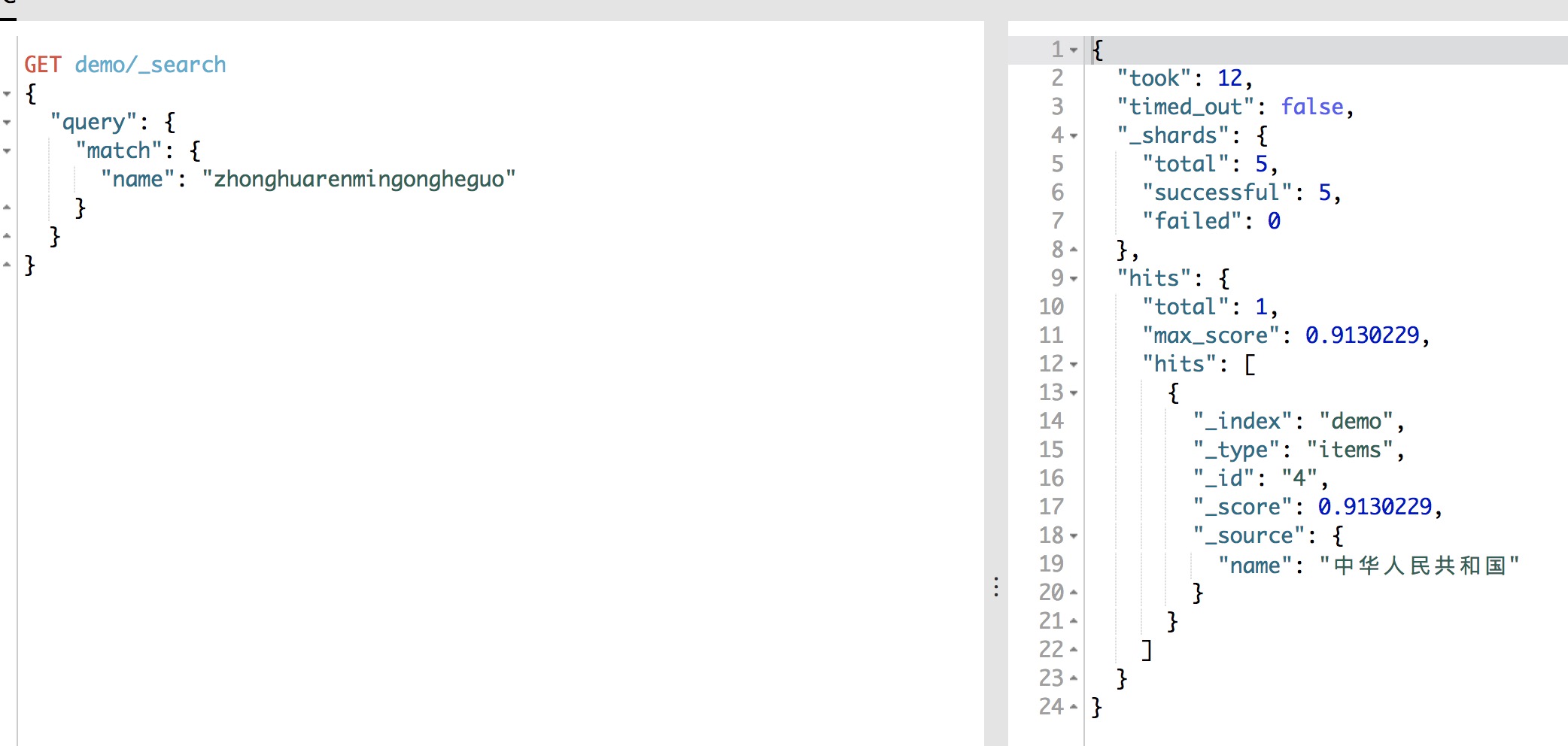
使用match搜索“中华人民共和国”的全拼音结果如下图
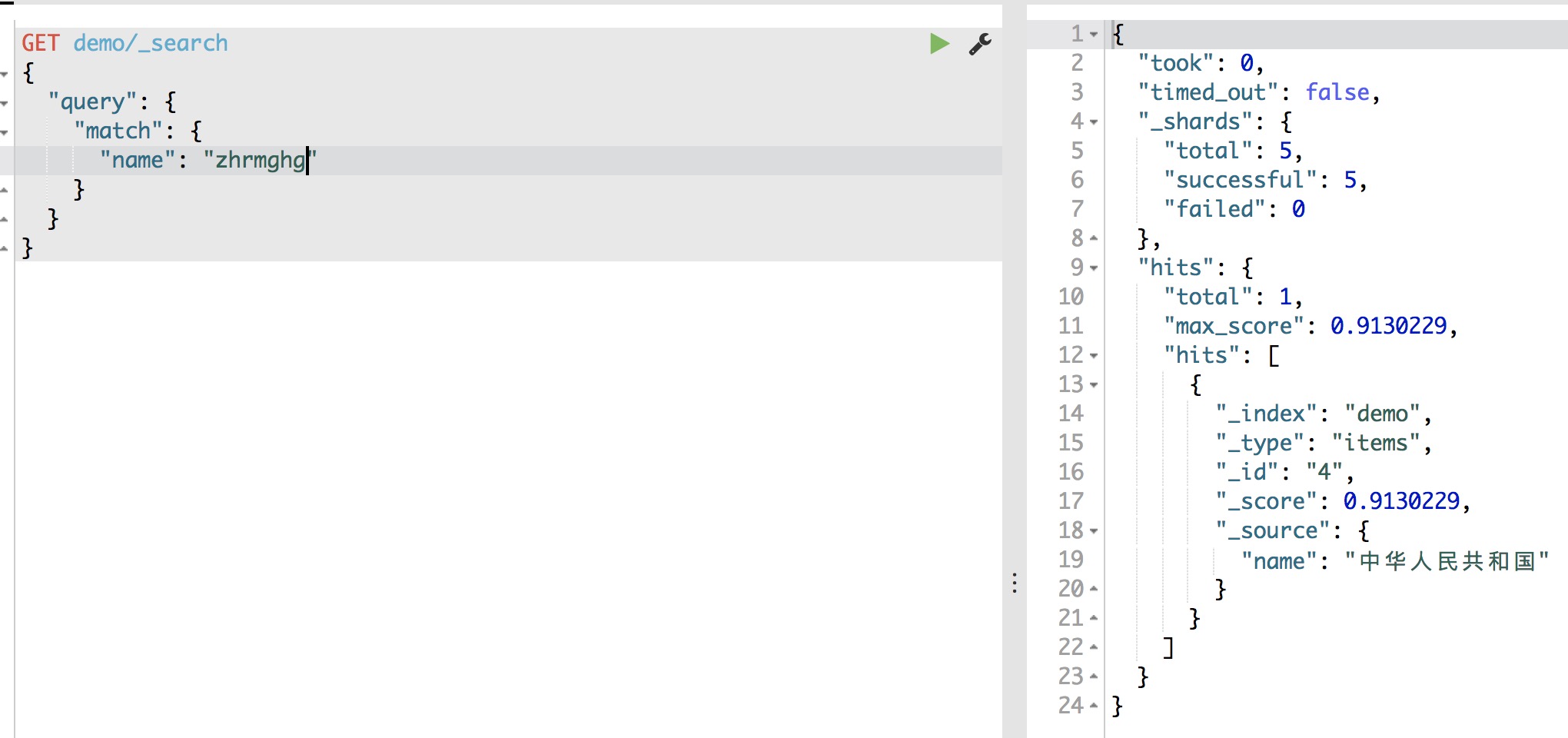
使用match搜索“中华人民共和国”的拼音首字母结果如下图
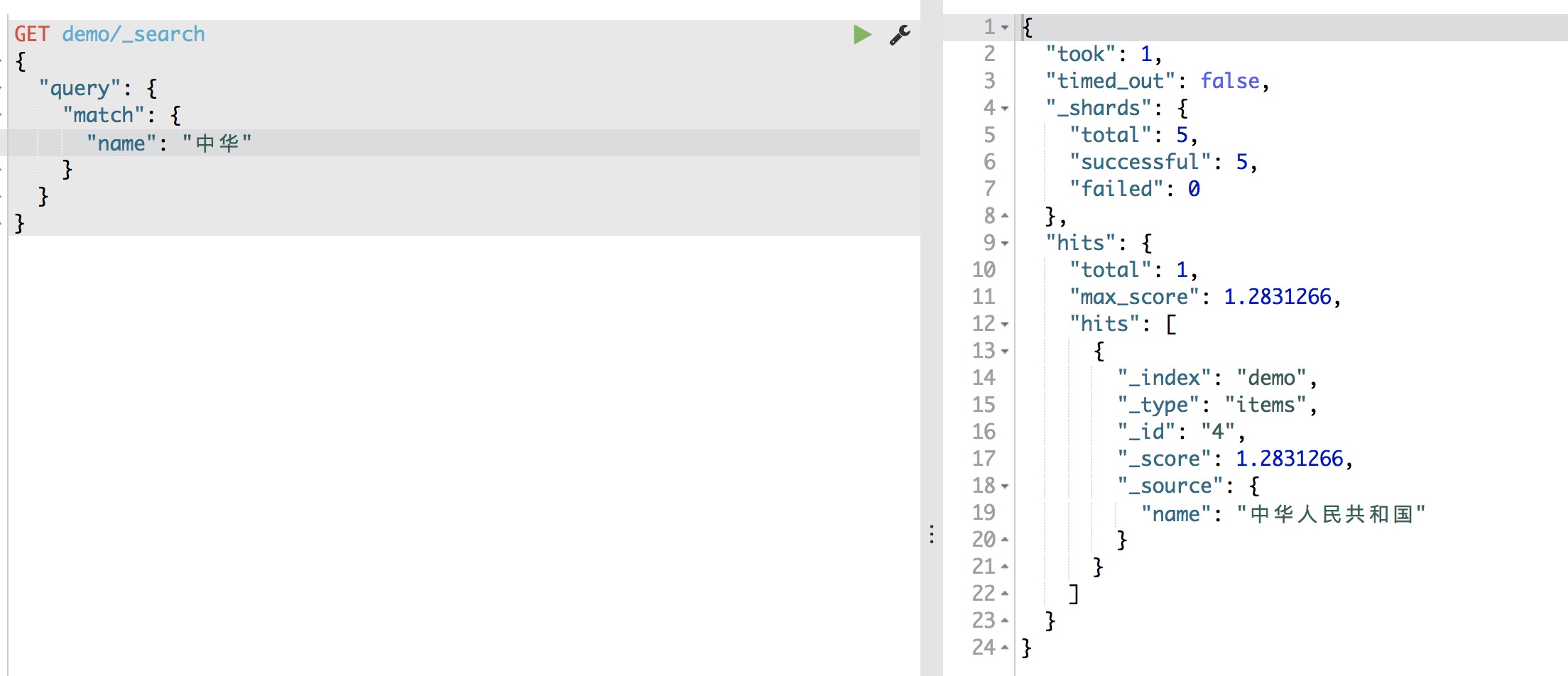
使用match搜索“中华”结果如下图
如果对IK分词器的效果不是很满意,可以自己整理语料,放入词库中,自定义词库路径为"config/analysis-ik/custom",同时需要修改IKAnalyzer.cfg.xml文件,在该文件中配置自定义词库的读取
推荐一个分词工具,个人认为挺好用的,是由梁斌老师提供的基于深度学习的中文在线抽词PullWord
