一直想研究spark源码来着,希望自己也能坚持下去吧。
先从github clone一份spark源码,我下载的源码版本是2.3.3版本。
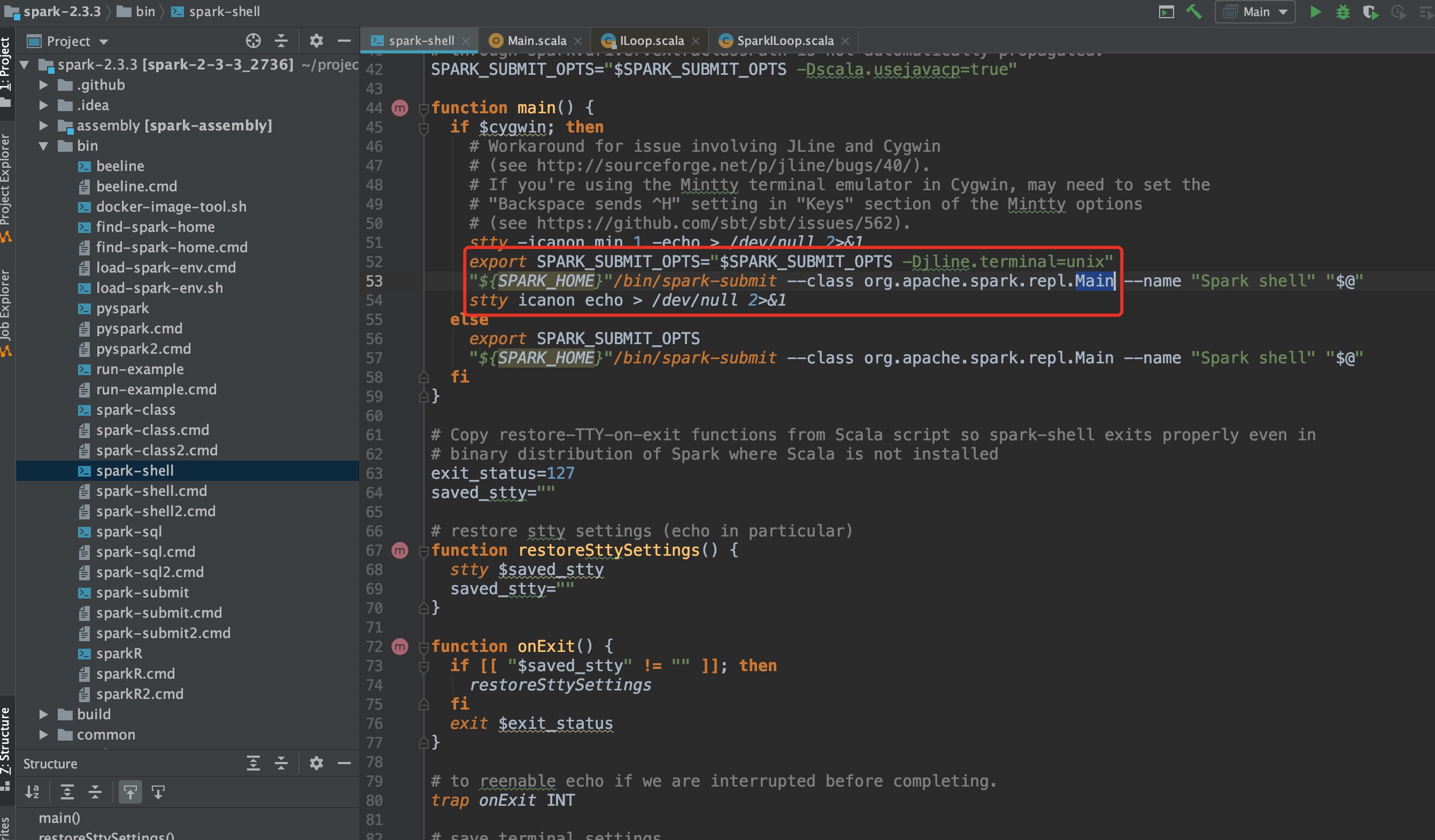
从图中,我们可以看到,用户在客户端执行spark-shell命令底层其实执行的还是spark-submit操作,相当于用一个shell包装了spark-submit。主类为org.apache.spark.repl.Main,该类位于spark-repl模块下。REPL的中文含义是交互式解释器,使用spark-shell其实就是交互式编程。
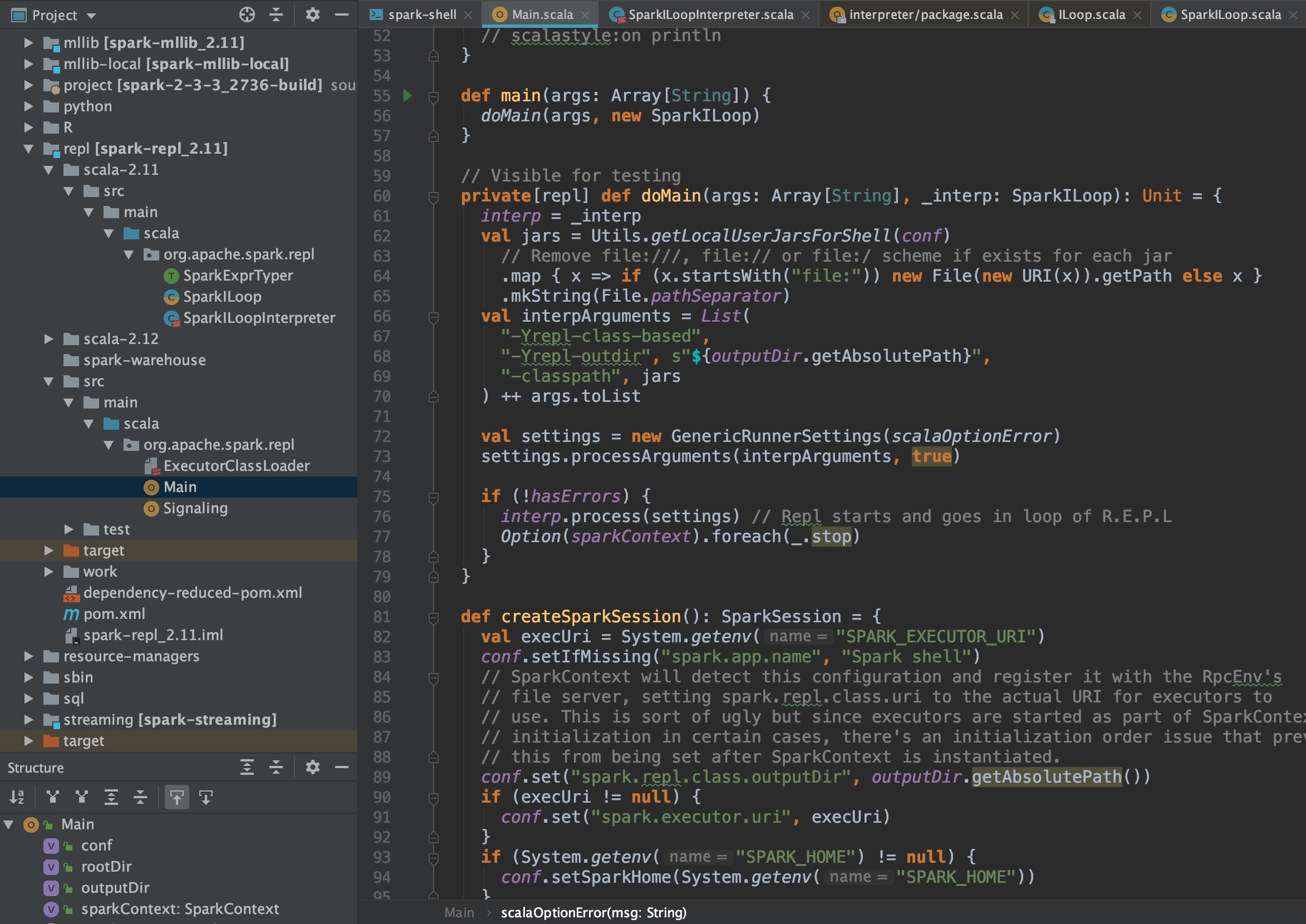
进入主函数,可以看到执行了一堆环境加载操作,最后执行interp.process(setting),调用SparkILoop类的process方法,该类继承自ILoop,process方法并未重写,进入父类查看process方法
// start an interpreter with the given settings
def process(settings: Settings): Boolean = savingContextLoader {
this.settings = settings
createInterpreter()
// sets in to some kind of reader depending on environmental cues
in = in0.fold(chooseReader(settings))(r => SimpleReader(r, out, interactive = true))
globalFuture = future {
intp.initializeSynchronous()
loopPostInit()
!intp.reporter.hasErrors
}
loadFiles(settings)
printWelcome()
try loop() match {
case LineResults.EOF => out print Properties.shellInterruptedString
case _ =>
}
catch AbstractOrMissingHandler()
finally closeInterpreter()
true
}
又是做了很多初始化工作,接着加载配置文件loadFiles(settings),该方法在SparkILoop类中被重写,在子类继承的方法中调用重写的方法,会调用SparkILoop重写后的loadFiles方法
/**
* We override `loadFiles` because we need to initialize Spark *before* the REPL
* sees any files, so that the Spark context is visible in those files. This is a bit of a
* hack, but there isn't another hook available to us at this point.
*/
override def loadFiles(settings: Settings): Unit = {
initializeSpark()
super.loadFiles(settings)
}
看方法名和注释都能知道,先初始化spark对象,再加载配置文件
val initializationCommands: Seq[String] = Seq(
"""
@transient val spark = if (org.apache.spark.repl.Main.sparkSession != null) {
org.apache.spark.repl.Main.sparkSession
} else {
org.apache.spark.repl.Main.createSparkSession()
}
@transient val sc = {
val _sc = spark.sparkContext
if (_sc.getConf.getBoolean("spark.ui.reverseProxy", false)) {
val proxyUrl = _sc.getConf.get("spark.ui.reverseProxyUrl", null)
if (proxyUrl != null) {
println(
s"Spark Context Web UI is available at ${proxyUrl}/proxy/${_sc.applicationId}")
} else {
println(s"Spark Context Web UI is available at Spark Master Public URL")
}
} else {
_sc.uiWebUrl.foreach {
webUrl => println(s"Spark context Web UI available at ${webUrl}")
}
}
println("Spark context available as 'sc' " +
s"(master = ${_sc.master}, app id = ${_sc.applicationId}).")
println("Spark session available as 'spark'.")
_sc
}
""",
"import org.apache.spark.SparkContext._",
"import spark.implicits._",
"import spark.sql",
"import org.apache.spark.sql.functions._"
)
def initializeSpark() {
intp.beQuietDuring {
savingReplayStack { // remove the commands from session history.
initializationCommands.foreach(processLine)
}
}
}
initializationCommands.foreach(processLine)调用processLine方法执行initializationCommands对象的每个元素,创建SparkSession对象,SparkContext对象,获取配置信息,然后打印,加载完配置文件后,执行process方法中的printWelcome方法,loadFiles和printWelcome方法执行完成后,用户就可以看到如下效果
/** The main read-eval-print loop for the repl. It calls
* command() for each line of input, and stops when
* command() returns false.
*/
@tailrec final def loop(): LineResult = {
import LineResults._
readOneLine() match {
case null => EOF
case line => if (try processLine(line) catch crashRecovery) loop() else ERR
}
}
接着执行loop()方法,loop方法内部调用readOneLine循环读取用户的输入,使用processLine处理用户的输入信息,发生异常catch时执行crashRecovery函数,比如import的包不存在之类的,可以恢复正常进行如上,processLine方法执行成功后继续调用loop方法,递归调用
loop方法还使用了严格尾递归检查注解。对于是否是严格尾递归,若不能自行判断,可使用Scala提供的尾递归标注@scala.annotation.tailrec,这个符号除了可以标识尾递归外,更重要的是编译器会检查该函数是否真的尾递归,若不是,会导致编译错误
如上就是spark-shell的整个执行流程