迁移阿里云过程中,部分表在阿里云上线,但是表的使用方原来是直接读取hive的数据,迁移阿里云后,表存在max-compute中,业务方读取max-compute比较繁琐,准备让业务方开发代码读取ES,由于业务方未开发完成,所以只能选取临时方案,考虑过用datax同步回hive,但是开源datax功能还是不完善吧,只支持orc,text格式的表,而且同步表不支持overwrite操作
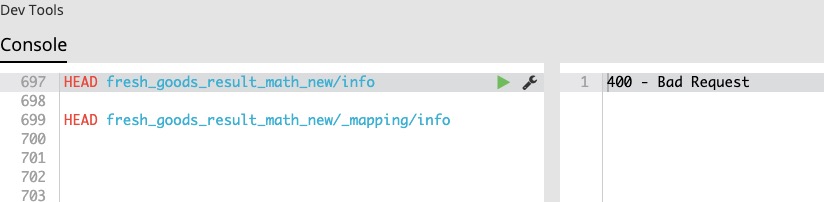
hive可以关联ES读取数据,而集群中有hadoop-elasticsearch的jar包,可以直接使用,在此记录下遇到的坑吧,我在集群中使用的jar版本是5.2.0版本,关联上ES表后,测试下查询功能,结果报错如下
通过报错信息可以知道,底层使用了head方式判断index/type是否存在,而ES 5.x版本中需要使用的是index/_mapping/type这种方式判断
可以看到ES 5.x版本中需要_mapping
再去github查看elasticsearch-hadoop源码,类elasticsearch-hadoop/mr/src/main/java/org/elasticsearch/hadoop/rest/RestClient.java
5.2版本中exists方法并没有对indexOrType做任何处理,直接请求
而从5.5版本开始,代码中会判断ES是否是5.x版本,是的话,使用index/_mapping/type方式,所以更换下集群中hive的包就行了,更换包的话,hive集群需要重启才会生效,也可以在hive命令行中使用add jar 的方式临时添加
hive中关联表的字段类型需要与ES mapping的类型严格一致,不一致时查询会报错,字段类型参考官方文档